6.828笔记 Lab 5: File system, Spawn and Shell
这一次的Lab主要实现文件系统,然后在此文件系统上加载可执行文件并执行,并基于此实现了一个简易的shell。
JOS文件系统简介
- JOS中的文件系统其实和大部分的现代操作系统的实现方式有很大的区别的,这里的实现方式是很简化了的,但是也足够让人理解文件系统的基本运行方式。这里是通过设置一个用户进程作为文件系统,给它操作I/O的权限,此用户进程常驻,其他用户进程(没有操作I/O的权限)要操作文件时通过IPC与其交互,文件系统用户进程对文件进行处理。
- 磁盘读写文件时不是按照字节为单位的,而是按照sector为单位的。在JOS中,sector为512字节。操作系统分配以及使用磁盘是以block为单位的,在JOS中,block是4096字节,和内存管理中一页的大小是一样的,方便后续操作。
- 文件系统一般会在磁盘中某个容易找到的地方放置superblocks,其中记录了block size, disk size等基本的信息。实际的操作系统中,会放置多份superblock以做冗余。但在此操作系统中,superblock只被放置在block 1的位置,也就是磁盘上4096字节开始的地方。而block 0的位置放置的是boot loader,分区表等信息。
- 此操作系统用如下图的
File struct来描述一个文件或目录/文件夹。在此结构中使用f_type来区分是文件还是目录。此结构只是描述文件的,而文件的具体内容存放在f_direct数组指向的block中。由于f_direct数组是固定大小的,大小超出此范围的文件由f_indirect管理。f_indirect指向一个block,在此4KB的block中以4字节为单位,共存储1024个值,每个值又指向一个block,所以f_indirect最大能容纳4KB*1024=4MB大小的内容。而对于目录来讲,存放的具体数据是在此目录下的文件/目录的File struct,一个block最大可以存放4096 Bytes/256 Bytes(File struct的大小为256字节) = 16个File struct。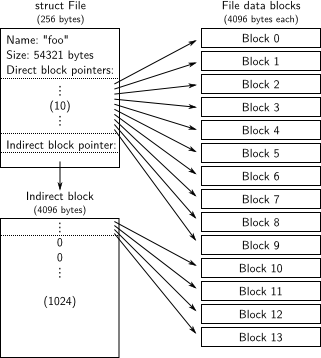
- 整体的磁盘空间划分如下。共N个block,从block 2开始的free block bitmap是以block为单位管理所有磁盘空间的,这个在后面会讲到。free block bitmap后面的内容就是放
File struct以及具体的文件数据。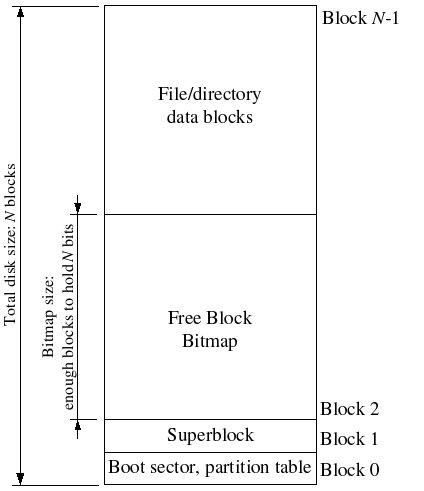
The File System
The Block Cache
文件系统用户进程是可以对文件进行操作的。具体来讲,把文件从磁盘加载到内存中,在这里,就是加载到文件系统用户进程的虚拟内存中。在之前的Lab中也讲到,一个进程的虚拟内存共4GB,其中会有代码段、数据段、堆栈等。在这里,使用从0x10000000到0xD0000000共3GB的地方映射文件(所以本操作系统最大支持3GB的磁盘空间),这一区域叫做block cache,由fs/bc.c进行相关的操作。在inc/memlayout.h中给出了用户进程内存空间的结构:
1 | UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE |
可以看到,从0x10000000到0xD0000000都是在堆栈区,并不会占用到其他必要的内容比如代码段等,而且也给堆栈留下了一定的空间。磁盘上block n位置上的内容加载到内存后被映射到文件系统用户进程中0x10000000+n*4096的位置。
一次把磁盘上的所有文件全部读到内存中是要很长时间的,而且有部分内容在后面也不会被用到,会产生浪费,所以刚开始并不加载磁盘上的全部内容。在运行的过程中,如果文件系统用户进程访问block cache中指定地址时发生内存缺页错误,则通过之前的set_pgfault_handler()函数转到指定的缺页处理函数bc_pgfault()。此函数在发生缺页的地方(要访问的文件在磁盘中的位置与block cache中相对应的地方)分配一页,通过ide_read()读取磁盘上指定位置的数据到刚分配的那一页上。最后清除PTE_D(dirty bit)。flush_block()也很简单,如果给定地址在内存中且被写了(文件被读取到内存中且被修改了),就把这一页的内容写回到磁盘中,然后清除PTE_D。
The Block Bitmap
block bitmap是用来管理磁盘上的所有block的。共有3GB/4KB=786432个block。按照一般的做法,可以使用一个长度为786432的数组来进行管理,值为1表示空闲,0表示在使用中。但是数组中一个元素就32位(假设是int数组),很占空间。实际上可以只用一个bit表示一个block,此时就只需要786432bits=786432/8=98304Bytes=98304/1024=96KB=4KB*24,也就是需要24个block来管理所有的block。至于怎么操作bitmap,网上一搜都有,所以在这里就不讲了。需要注意的一点是alloc_block()中修改bitmap中的一位为0(代表使用中)后,需要把这一位所在的block马上写回到磁盘中。
File Operations
主要是完成file_block_walk()和file_get_block()。fs/fs.c里面其他文件操作的函数会用到这两个函数。file_block_walk()就是对于给定的File struct *f,找到其第filebno个block,必要时要分配f_indirect。file_get_block()使用了file_block_walk(),更进一步地,如果得到的block为0,即这一页还未分配,就分配一页并在f_direct或者f_indirect做映射。
The file system interface
由于之前说了,只给了文件系统用户进程I/O权限,其他普通用户进程要做文件操作时需要通过IPC与文件系统用户进程进行交互。具体过程如下(以open()为例):
- 文件系统用户进程做了一些初始化后,在
while(1)里面进行ipc_recv(),接收到的共享页映射到此进程的fsreq(0x0ffff000),也就是还有一页就到0x10000000(开始映射文件的地方)。 - 用户进程调用
lib/file.c/open(),分配一个从0到31的fd number,此fd number对应在虚拟内存中有一个PAGESIZE的位置存放struct Fd。设置内存中union Fsipc fsipcbuf的相关值,如对于open()来讲就是文件路径和打开模式。最后调用ipc_send()发送操作类型(FSREQ_OPEN)和fsipcbuf(用来共享)到文件系统用户进程。 - 普通用户进程进入内核后,把
fsipcbuf的物理页映射到文件系统用户进程的fsreq,并把操作类型这个数值通过IPC发送给文件系统用户进程。 - 文件系统用户进程结束
ipc_recv()后,根据操作类型选择不同的函数进行执行。对于open()来讲就是新建/打开一个文件,在内部维护相关的数据结构,准备给用户进程返回此文件的struct Fd。 - 文件系统用户进程调用
ipc_send(),给请求文件操作的用户进程发送第4步中设置的struct Fd页面,实现了file descriptor的共享。 - 用户进程在第3步结束
ipc_send()以后,调用ipc_recv(),接收第5步文件系统用户进程发送的ipc_send(),并把发来的共享页面Fd映射到此Fd在内存中对应的位置。 - 用户进程拿到
Fd后,结束open()操作。同时文件系统用户进程取消在第3步中fsreq的映射,并在while(1)中继续下一次的ipc_recv()。
以上是open()操作的过程。其他的操作比如read(), write()和open()差不多,read()和write()中把读到的数据和要写的数据直接放在union Fsipc中相关的buffer里,并且没有第5步第6步中Fd的共享(因为read()和write()时用户进程已经有Fd了)。
Spawning Processes
目前的操作系统能在内核中指定加载某个程序,或者在用户程序中使用fork(),但是并不能够加载文件系统中已有的程序,这一步就是做这个的。lib/spawn.c可以在一个用户进程中创建一个新的用户进程,从文件系统中加载指定的镜像(可执行文件)到新进程,然后开始执行此新进程。这个函数就像linux中先使用fork,然后在子进程中使用exec。lib/spawn.c中有一个spawnl()函数,这个函数的主要功能是使用可变参数解析输入进来的参数,最后把prog(在新进程中要加载的镜像)和argv(处理好以后的参数数组,最后一位是NULL)输入给spawn()。spawn()函数的主要操作是:
- 打开给定的镜像文件。
- 创建一个新进程。
- 新进程初始化栈。
- 分配页,把镜像文件中的segment映射并写入到内存中对应的地方(这里是把可加载的segment全部加载进内存,就像
kern/env.c/load_icode()一样)。 - 设置共享页面(这个在下面会讲到)。
- 设置新进程的
trapframe。 - 设置新进程的状态为
ENV_RUNNABLE。
这里主要讲一下3和6。
初始化进程栈的代码是Lab中提供了的,结合代码和《程序员的自我修养——链接、装载与库》第6章:可执行文件的装载与进程,弄懂了初始化栈是怎么进行的。在这里,对于一个新进程,输入的只有参数,也就是argv,共有argc个,每个都可以看成是字符串。假设共2个参数,分别为hello和12345,其字符串加一起是4字节对齐的,那么初始化后的栈如下: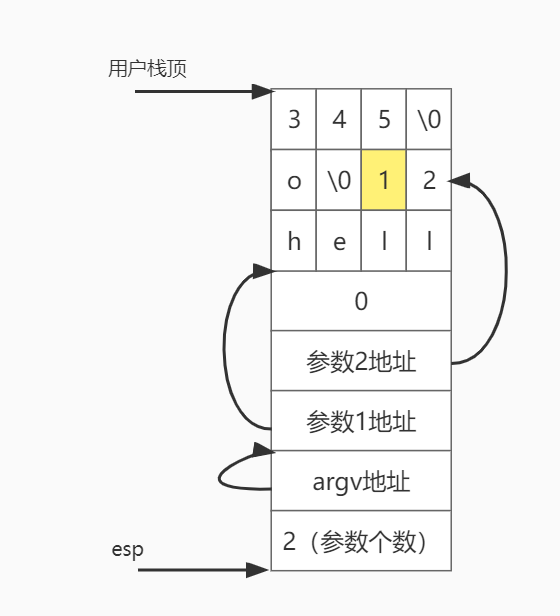
esp指向栈底,此位置放的是argc,也就是参数个数2。然后是argv数组的地址,也就是再往上4字节的地方。接下来分别是2个参数指针,指向参数的地址,这里已经用箭头标出来了。其中参数2的地址应该是上面黄色方块1的地址,只不过这里画不过去。两个参数指针结束后是一个0,后面就放的是参数字符串。《程序员的自我修养——链接、装载与库》中与这里有一点不一样,书中少了argv数组的地址,多了环境变量字符串和其对应的指针和后续的一个0。不过基本原理差不多。
此时设置了esp,还需要设置其他寄存器的值。比如设置eip为可执行文件的入口地址,在kern/syscall.c/sys_env_set_trapframe()设置eflags中的一些位。
做了以上的设置后,就可以在用户进程中直接加载别的可执行文件了。这里有一点问题:上面第4步写到,加载镜像文件时是一次全部加载进内存的。我想能不能改成初始化时只做映射,遇到page fault后再加载进来。如果这样做的话就需要知道该进程对应的是哪个可执行文件。但是在进程结构Env里并没有这样的字段。如果不修改内核,可以在page fault处理程序中写死对应的可执行文件。但是即使这样,也并不知道发生page fault的地址对应在可执行文件中的哪个部分,除非是把此地址和可加载的segment一个一个地做对比,看是哪个segment里的内容。但这样做每次page fault时都要打开文件,还不如一次把可执行文件中的内容加载完。
Sharing library state across fork and spawn
这里的目的是在fork和spawn产生的子进程与父进程之间共享file descriptor。而对于file descriptor,可以在fs/serv.c/serve_open()里面看到,返回给普通用户进程的Fd页面的权限里有一个PTE_SHARE。而这一节就是需要在fork和spawn里添加对PTE_SHARE的额外操作:如果此页面是PTE_SHARE的,就直接复制映射关系到子进程,实现了共享。
The Shell
这一节是我感觉最有意思的地方。因为这里是把之前写过的东西都用起来了,而且还真正地跑了一个shell程序,可以输入命令,它也会去执行。到这里,一个操作系统的雏形好像才真正出来了。
Lab中说运行make run-icode。运行这一句后的操作流程为:
- 启动操作系统,创建文件系统用户进程,创建
user/icode.c对应的进程。 user/icode.c使用spawn创建user/init.c对应的进程,user/icode.c之后结束进程。user/init.c是用户进程的初始化代码。先做一些检查后,然后打开两个console,文件描述符分别为0和1,分别代表标准输入和标准输出。但是代码里面实际上只打开了一次,获取Fd为0的后,直接把Fd为0页面的映射到Fd为1的地方,且两个的权限都是读写。然后再spawn了user/sh.c,即shell程序。user/sh.c在while(1)从Fd0(此时的Fd0还是console)接收字符串,然后fork一个子进程,让这个子进程运行runcmd(),参数就是刚刚接收到的字符串。- 运行
runcmd()的子进程解析字符串,也就是刚刚输入的命令,解析好以后,再spawn对应的子进程。spawn出的子进程才真正执行命令。
Lab中让实现输入重定向,具体命令是sh <script。script是已经写好的几行命令文件。就是需要在第5步解析字符串的时候,如果解析到<,则再解析下一个参数,也就是输入源文件。把这个文件打开,此时的Fd本来是2(fork和spawn时的Fd都是共享的,所以此时和第3步设置的0和1是相同的,再打开一个文件Fd只能为2),然后使用dup(fd, 0)(dup(int oldfdnum, int newfdnum)是把oldfdnum对应的物理页面映射到newfdnum的位置,实现这两个Fd的共享)把新打开的文件放在Fd0的位置,关闭Fd2。这样其子进程user/sh.c读取数据时就对应了第4步中的Fd0,也就是script中读取了,而不是console。
做的时候我发现了一个问题,就是第一次在shell里运行sh <script后,在其子进程中Fd0已经被修改为script了,而Fd都是共享的,所以按理讲,script里面的命令执行完了以后第4步中执行while(1)的user/sh.c就不能再从console中输入了,除非再显式地设置Fd0为console。但是代码里并没有这样做。我找了一会儿,才发现解析到<进行dup(2, 0)时,是先要close(newfdnum)的,也就是先取消映射Fd0(此时就和父进程的Fd0不共享了),然后再把Fd2映射到Fd0。这样就可以在不影响父进程的情况下修改标准输入输出。>的原理差不多,也是修改标准输出为指定的内容(比如设置输出到指定文件中),之后可以输出的命令(如user/cat.c,如果不给此命令其他参数,就从标准输入0中读取数据,否则从给定的文件中读取数据,然后输出到标准输出1:write(1, buf, n))的标准输出已经被修改了,这就实现了输出重定向。
管道|就更有意思了。父进程A和子进程B都修改标准输入输出。比如A修改标准输出,执行|左边的内容;B修改标准输入,执行|右边的内容。而这两个修改的Fd对应的读和写操作都是在同一个物理页面上进行的,所以A输出的内容B就能找到并输入。此时,A的输入和B的输出都还没有变,都还是console。
这一段是很有意思的,但是由于细节太多,设计地很精妙(也可能是因为我见过的好的代码太少),就比如上面dup()里面取消映射newfdnum的操作,再比如管道的具体代码,我全部记下来也没有多大意义,所以就不再写了,后面如果再想看了可以直接去看代码。
The End
好了,这次的Lab5到这就基本上结束了。这次和上一次之间隔的时间最长,有两个多月。中间寒假回去做了大部分,但是有些细节的代码都还没怎么看,只是能过Lab的测试了,所以当时就没写。回到学校后,前面一段时间有点忙,没看,后面有时间了又从头看了一遍,之前没看的代码也都过了一遍。
到这里就实现了一个操作系统从启动内核,到启动用户进程的shell,用shell在用户和内核之间交互。后面的Lab6网络部分目前就不会再继续做了,因为我看了下,好多都是一些驱动相关的,比较硬,比较麻烦,我自己对那部分也不太感兴趣。而Lab7就是最后的大作业,自己完善一些功能。后面其实能做的还有很多,就比如继续实现一些shell命令、多线程、多用户、堆等。但是这些我估计暂时就不会做了,以后如果有时间了可以继续完善。
通过这一系列的Lab,我确实学到了很多。感谢所有提供学习资源的人。🙏