6.828笔记 Lab 4: Preemptive Multitasking
Lab4主要分为三个部分。第一部分扩展JOS支持多CPU,实现轮转调度,添加了几个基本的进程管理的系统调用。第二部分实现了一个Unix-like的fork()。第三部分是抢占式多任务处理和进程间通信。
Multiprocessor Support and Cooperative Multitasking
Multiprocessor Support
这一步部分主要涉及对称多处理SMP(symmetric multiprocessing)。这种处理方式能够让所有的CPU有相同的权限/机会去获取系统资源,比如内存,I/O总线等。但是在启动阶段,这些CPU不是对称的,分为bootstrap processor(BSP)和application processors(APs)。BSP负责初始化,启动操作系统;AP则在BSP启动操作系统后才会被BSP启动。在多处理器下,哪一个CPU是BSP是由硬件和BIOS决定的。之前写的代码只有一个CPU,这个CPU一直是BSP。在SMP中,每一个CPU都有一个对应的local APIC(LAPIC)单元。LAPIC负责给系统传送中断。
那些LAPIC以及其他的和SMP相关的代码先不看,主要是因为看不懂。就直接看kern/init.c里的初始化过程。一个BSP执行完前面的一些初始化后,跳转到函数boot_aps()。这个函数会启动APs。首先通过
1 | code = KADDR(MPENTRY_PADDR); |
把kern/mpentry.S的代码复制到MPENTRY_PADDR处(0x7000,所以Lab会让修改kern/pmap.c/page_init(),不把这个地方的页加入page_free_list)。然后对于每一个AP,通过lapic_startap()函数发送startup IPI给对应的LAPIC。然后对应的AP会开始执行kern/mpentry.S,并且是以实模式启动的(之前把kern/mpentry.S的代码复制到0x7000处就是因为如果放的位置太高了,实模式下是寻址不到的)。kern/mpentry.S和boot/boot.S类似,都是启动CPU的。但有几点需要注意:
kern/mpentry.S里用了这么个define:这是因为现在这份代码里用到的符号的地址是经过链接器处理,是虚拟地址。而现在CPU是实模式,只能通过真实物理地址来寻址,所以做这么个变换。1
- 每个CPU都会设置自己专属的内核栈,这个下面会讲。
最后AP会跳转到kern/init.c/mp_main(),在这里面再做一些初始化设置后,把CPU的状态置为CPU_STARTED。在上面AP运行的过程中,BSP在kern/init.c/boot_aps()中一直是
1 | while(c->cpu_status != CPU_STARTED) |
BSP接收到CPU_STARTED的信号后,才开始启动下一个AP。此时刚才刚被启动的AP会开始去调度进程(找到一个状态为ENV_RUNNABLE的进程,env_run()执行它。具体的下面会讲)。
Per-CPU
每一个CPU都会有自己的一些状态,寄存器等,这些在kern/cpu.h里有定义。需要改代码的是关于CPU的内核栈,每个CPU都需要一个单独的内核栈,具体的分布如图
1 | 4 Gig --------> +------------------------------+ |
之前是把BSP的内核栈和CPU0’s Kernel Stack对应,现在需要把一定数量的CPU的内核栈分别和0,1,2……来对应,所以需要为这些CPUx’s Kernel Stack分配物理地址并映射。在kern/trap.c/trap_init_percpu()里也要做对应的修改,把对应的内核栈的位置修改了:
1 | int cpuid = cpunum(); |
加锁
加锁后,同一时间只能有一个CPU上的一个进程进入内核,其他的要进入内核的都需要等待。否则有可能不同的进程会资源竞争,导致死锁等情况。对于在MSP下,对于BSP和每一个AP,都要在进入内核前加锁,返回用户态前解锁。加锁时如果有其他的进程已经在内核态了,就等待。具体加锁解锁的时候在Lab中都讲了,所以这里就不说了。
Question: It seems that using the big kernel lock guarantees that only one CPU can run the kernel code at a time. Why do we still need separate kernel stacks for each CPU? Describe a scenario in which using a shared kernel stack will go wrong, even with the protection of the big kernel lock.
这是因为在发生中断异常时,在kern/trap.c/trap()加锁前,已经由CPU和kern/trapentry.S在内核栈上放了当前进程的寄存器值,即保存上下文。如果不同的CPU共享一个内核栈,那么多个CPU同时发生中断异常时,在kern/trap.c/trap()加锁前放寄存器值时就会把栈弄乱。
轮转调度
用户代码通过系统调用sys_yield()来进入内核的sched_yield()函数,即调度函数。这个函数搜索管理进程的数组envs,找到第一个状态为ENV_RUNNABLE的进程,然后env_run()。如果没有可执行的进程,就会进入内核。
注意:
- 每一个CPU都会进行调度,一个进程在一个CPU上运行了,此时就不会在另一个CPU上运行。即一个进程不能在两块及以上CPU上同时运行。所有的进程都是整个操作系统来管理的,不同的CPU只负责找到一个
ENV_RUNNABLE的进程并执行就行了。 - 这种方式是主动的(正如标题Cooperative Multitasking),必须要用户进程A调用
sys_yield()函数来放弃当前CPU的使用权,CPU才能处理下一个进程B。之后B再调用sys_yield()后,又会在envs数组中找到进程A,从之前打断的地方继续运行。 - CPU上当前的进程不管处于什么原因,被
env_destroy()后,此CPU也会调用sched_yield(),来寻找下一个可运行的进程。
Question: In your implementation of env_run() you should have called lcr3(). Before and after the call to lcr3(), your code makes references (at least it should) to the variable e, the argument to env_run. Upon loading the %cr3 register, the addressing context used by the MMU is instantly changed. But a virtual address (namely e) has meaning relative to a given address context–the address context specifies the physical address to which the virtual address maps. Why can the pointer e be dereferenced both before and after the addressing switch?
这是因为变量e是在内核栈中的(在内核态下当然使用的是内核栈)。而在kern/env.c/env_setup_vm()中,每一个进程在初始化时都会把页表中UTOP以上除了UVPT的地方都映射到和kern_pgdir相同的地方,所以,变量e所在的页,不管是在内核页表还是用户进程页表中都会映射到相同的物理地址,所以切换前后都能访问到。
进程管理的系统调用
在上面的代码中,实现多进程的方式都是BSP在内核中调度进程前创建多个进程,如
1 | // Starting non-boot CPUs |
用户并不能自己创建,所以在这一节中实现了几个系统调用,使用户进程也能创建用户进程。
Unix的fork()时把父进程的空间都复制一份给子进程,父进程的fork()函数的返回值为子进程的进程id,子进程的fork()函数的返回值为0。在这里需要先实现以下几个系统调用:
sys_exofork:
通过env_alloc()创建一个进程(子进程),只修改其状态为ENV_NOT_RUNNABLE;赋当前进程(父进程)的寄存器值给这个新进程的寄存器;子进程的eax设置为0(eax放的是系统调用的返回值,设置为0就可以实现父进程通过系统调用函数返回子进程id,子进程返回值为0)。sys_env_set_status:
设置进程的状态为ENV_RUNNABLE或ENV_NOT_RUNNABLE。调用此系统调用的进程A必须是要被设置的进程B本身或是其的父进程。下面的几个系统调用都要遵守这样的规定。sys_page_alloc:
分配空白的一页,将其映射到给定进程的给定虚拟地址上。sys_page_map:
将源进程的源虚拟地址对应的物理页映射到目标进程的目标虚拟地址对应的那一页上。在此过程中,最多修改目标进程的页表,不会分配写实际内容的页。sys_page_unmap:
将进程的给定虚拟地址取消映射。
为什么一次fork()会返回两个值?
1 | static envid_t |
新建了一个进程,并设置新进程的父进程就是当前进程后,除了eax设置为0,其他寄存器和当前进程设置相同。父进程通过正常途径返回到用户态,此时子进程的状态还是ENV_NOT_RUNNABLE。父进程做一些映射后,设置子进程为ENV_RUNNABLE了,下一次CPU调度的时候就会运行子进程,此时子进程的寄存器和父进程系统调用前的一样,直接执行下一条指令。用户代码中
1 | envid = sys_exofork(); |
此代码对应的汇编代码为
1 | 8000e8: b8 07 00 00 00 mov $0x7,%eax |
$0x7是sys_exofork()的系统调用号,保存在eax中。父进程是通过int指令正常返回,返回后把eax里的返回值mov到ebx。子进程执行时,eip为8000ef,就直接执行mov,所以形成了调用一次返回两次,并且两个返回值不同的现象。
Copy-on-Write Fork
之前的fork是把父进程所有内存页上面的数据全部复制到子进程的内存页对应的位置上,然而,在fork后经常会使用exec等函数,用别的程序替换子进程的内存内容,所以之前的复制是一种极大的浪费。所以之后使用写时复制(copy on write):即初始化子进程时,只是把父进程的页表映射关系复制到子进程的页表,并不复制其具体内容。然后把这些共享的页标记为只读,Copy-on-Write(COW)。然后父/子进程中的任何一个修改这些只读页时,生成一个page fault。此时操作系统再为生成page fault的进程分配一个新的、可写的、含有这一页内容的页。这样做就降低了在fork后使用exec的开销。
User-level page fault handling
之前Lab3中加载进程时是一次把所有内存页内容加载进内存。但是在实际上,加载新进程时一般只分配用户栈一页,其他页只在页表中做了映射,并不分配页并写入。在实际执行程序要用到哪一页时,发生page fault,操作系统再次做处理。对于不同类型的page fault,处理方法不同。如栈发生page fault了,就分配并映射新的一页;代码段page fault了,就到可执行文件中读取对应位置的内容写入到一页,并映射到对应位置。这在《程序员的自我修养——链接、装载与库》的第6章可执行文件的装载与进程中也讲到了。
所以需要让操作系统知道发生page fault时需要做什么。在这里,发生page fault时handler的操作过程是自定义的。要实现User-level page fault,整个操作流程如下:
- 进程使用
sys_page_alloc系统调用为异常栈(User Exception Stack,异常栈还是属于用户空间,但是和正常栈区分开了)分配空间,使用sys_env_set_pgfault_upcall()系统调用为进程设置发生page fault时要转入执行的函数,并在同时设置_pgfault_handler,即真正的处理程序。 - 发生page fault时,在
kern/trap.c/page_fault_handler()中在异常栈上建立一个UTrapframe结构,然后把当前进程的eip指向之前设置的env_pgfault_upcall,当前进程的esp指向刚刚设置的UTrapframe底部。这样就可以在异常栈上执行env_pgfault_upcall程序。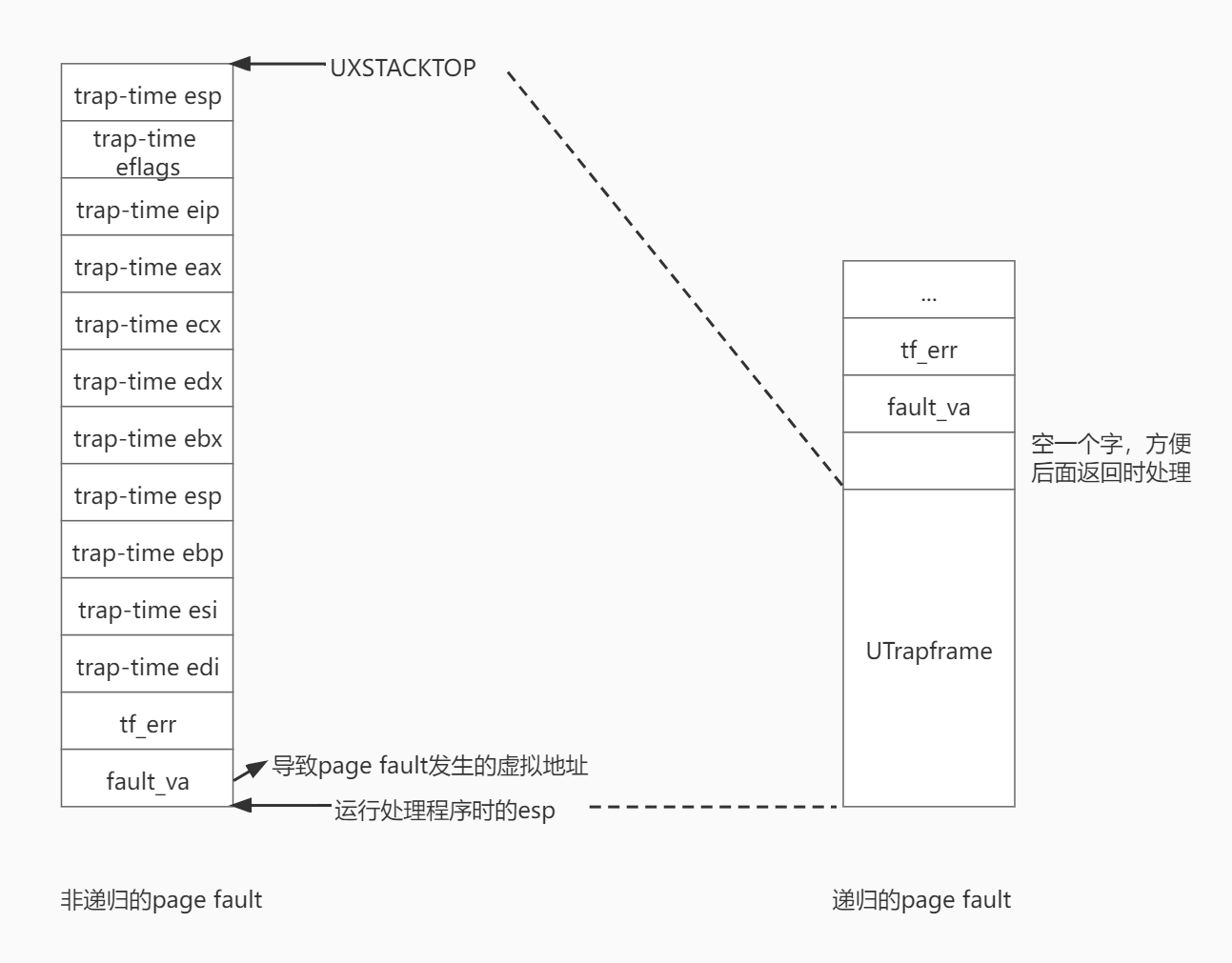
- 由于
env_pgfault_upcall统一指向的是lib/pfentry.S/_pgfault_upcall,所以从这个汇编语言开始执行。在_pgfault_upcall中,调用_pgfault_handler,使用用户自己定义的处理程序处理,在此处理程序中,处理方法是自定义的。处理完成后,从异常栈直接返回到正常用户栈。
如果发生page fault的地址就在异常栈中,即处理page fault的程序运行时又递归地发生了page fault,则第2步中建立UTrapframe结构时顶部不是UXSTACKTOP,而是当前esp下面空一个字的位置。这样做是为了在递归page fault时,在后面第3步能够正常返回到正常用户栈。具体怎么返回的就不展开讲了,方法比较巧妙,算是一个trick。
Copy-on-Write Fork
至此已经实现了Copy-on-Write Fork所需要的基础的功能。fork()的具体操作步骤如下:
- 调用
set_pgfault_handler()分配、映射异常栈和设置env_pgfault_upcall,并设置_pgfault_handler为pgfault()(此函数在后面讲)。 - 使用
sys_exofork()创建一个子进程。 - 扫描父进程中从
UTEXT到USTACKTOP之间所有的页,如果在父进程中是可写的或是COW的,把子进程中对应虚拟地址映射到同一物理地址,并标记为COW,然后在父进程中标记为COW,此时不能写,但可读,又和只读区分开来;对于父进程中只读的页,就在子进程中直接映射为只读。 - 给子进程分配映射异常栈。
- 给子进程设置
env_pgfault_upcall。 - 设置子进程的状态为
ENV_RUNNABLE。
这其中卡住我时间最长的是第3步,Lab和代码中让使用uvpt和uvpd查看页表的权限位。我刚开始实在是没能理解怎么用,代码中的注释也看得迷迷糊糊的,然后卡了好久。后来输出了一下,显示uvpd是0xef7bd000,uvpt是0xef400000,最后是从这下手弄懂的。
uvpd0xef7bd000的二进制为1110 1111 0111 1011 1101 0000 0000 0000,根据内存管理部分,此地址的前10位1110 1111 01(11 1011 1101),也就是3bd用于在Page Direction中索引。而在kern/env.c/env_setup_vm()中其中1
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
UVPT为0xef400000,PDX也就是前10位也为3bd。所以用0xef7bd000寻址时第一步查找的结果又回到了Page Direction本身。第二步的PTX还是3bd,又回到了Page Direction。虚拟地址的后12位指出一个4KB的页中的具体偏移量,所以通过uvpd的后12位就可以直接访问此进程的4KB的Page Direction的每一个字节了。作为Page Direction共1024项,每一项32位,4个字节,由于内存寻址时是按字节为单位的,而要得到的PTE信息是以字为单位的,所以最后面两位恒为0。前面10位表示1024项,后面2位为0,所以共(2^10)*(2^2)=2^12(4KB)。也可以直接使用uvpd[n]来访问第n个字(32位的),n的取值范围为0~1023。- 而
uvpt的二进制为1110 1111 0100 0000 0000 0000 0000 0000,第一步回到了Page Direction,第二步全为0,但是可以自己加,这10位可以取0到1023,即Page Direction中所有的Page Table的地址(前提是此Page Table是存在的),最后可以在后面斜体的10位0上设置偏移量,查找Page Table中1024项的数值。
举个例子,就比如地址addr为0xeebfd000,二进制为1110 1110 10 11 1111 1101 0000 0000 0000,寻址时,
- 第一步为用粗体数字3ba在
Page Direction中查找这一项是否存在。而在这里,就可以使用1110 1111 01 11 1011 1101 1110 1110 1000,也即uvpd[0x3ba]在Page Direction中查看这一项是否存在(uvpd[0x3ba] & PTE_P)以及获得权限位(uvpt[0x3ba] & 0xFFF)。 - 寻址时第二步还要看在3ba对应的页表中上面斜体的3fd项是否存在。这一次就可以用1110 1111 01 11 1011 1010 1111 1111 0100来查看:若这个
Page Table不存在,则在第二步用3ba寻址时就page fault,否则找到3ba对应的Page Table,再查看第3fd个字的具体内容(高20位为这一页映射到的物理地址,低12位为权限位)。也可以用uvpt[addr>>12]表示,addr>>12,就只剩下了高20位,[]取一个字,相当于乘4,即左移2位,最后就是uvpt+(addr>>10),就是上面的第二步拼出来的地址。
最后这一段写出来的代码为
1 | for(addr = UTEXT; addr < USTACKTOP; addr += PGSIZE) |
右移12位也相当于取PGNUM。
我把这段写出来后才弄懂了,他给出uvpt和uvpd,就可以在这两个地址的基础上通过改变PDX和PGOFF来定位到想要查询的Page direction和Page Table上的具体的项,最终是为了查找Page direction和Page Table中项的权限位,然后来确定哪一页在父进程中存在,哪一页不存在,对于存在的,映射到子进程中去。那为什么不直接用kern/pmap.c/pgdir_walk()这样的函数呢?后面试了一下才想起来,这是用户态代码,不能直接使用内核函数的,除非使用系统调用。
后面的操作就简单了,给父/子进程做映射、设置等直接用系统调用就可以了。
最后还要实现对COW页进行写操作导致page fault时的处理函数pgfault()。由于COW页A是父子进程共享的,所以不能写入,如果要写,则导致page fault,最后运行到之前定义的_pgfault_handler也就是pgfault():
- 在
pgfault()里面给要写入的进程e(e可以是父进程,也可以是子进程)分配新的一页B,并映射到e的一个临时的安全的地址。 - 把A的内容复制给B。
- 把B映射到A的地址,此时就把之前A的映射关系覆盖了。
- 把B在e中临时地址上的映射关系取消。
这样就定义好fork()和相应的page fault处理程序了。运行时也发现,用户栈会导致page fault,因为在fork()以后,还是会对自己的栈进行操作的,所以会page fault,然后用一个有写权限的页替代原来的。
Preemptive Multitasking and Inter-Process communication (IPC)
抢占式多任务
到目前为止,任务调度还是需要依靠进程自己在程序中使用系统调用sys_yield()来声明放弃CPU,然后操作系统找到另一个可运行的进程并运行,如果找不到别的可运行的就继续运行当前进程。这样做的坏处很明显,如果只有一个CPU,这个CPU当前运行的进程进入了一个死循环,在这里面不调用sys_yield(),那么操作系统是没办法收回CPU的。所以要使用抢占式的调度。即每过一段时间,时钟发出一个中断,操作系统对此中断的处理就是强制收回当前进程的CPU,换下一个进程进行调度。在这里,时钟每过一段时间发出一个中断这部分Lab中已经写好了,只需要注册这些中断信号就可以了。同时,eflags有一位FL_IF,为1时CPU能够接受外部中断(就比如时钟信号的中断),否则则屏蔽外部中断。在此操作系统中,在用户态时是设置为1,在内核态时设置为0。所以需要在初始化进程时设置此信号。按照Lab中的操作步骤和代码中的注释,参照Lab3中的注册方法,就可以实现了。
进程间通信
在这里的通信机制也比较简单,通信的双方都使用系统调用,一个接收信息一个发送信息。
- 接收方:通过系统调用,在内核中设置自己的接收信号位,设置自己的状态为
ENV_NOT_RUNNABLE,然后使用sched_yield()调度其他进程。这样操作系统就不会再运行此进程了,直到发送方在内核中设置接收方的状态为ENV_RUNNABLE。 - 发送方:做各种检查,如果能发送,则在内核中修改接收方进程的成员变量以存储接收信息,设置接收方的接收信号位,把接收方状态设置为
ENV_RUNNABLE。有一点需要注意,因为接收方最后sched_yield()了,所以后面的代码是不会执行了,要设置接收方的返回值,只能通过发送方在内核中设置接收方进程的eax为0,接收方才能正确返回。
上面写的是发送一个数字的过程,但是也可以传送页。比如接收方A设置接收的页要映射到自己空间的Aaddr,然后阻塞自己。发送方B有一页要发送给A,其在B的虚拟空间中的地址为Baddr,这一页的物理页实际地址为C。要把这一页发送给A,就在B进入内核,做一系列检查后,把Baddr对应的那一页C映射到A的Aaddr地址就可以了。这样就实现了两个进程的不同地址(也可以相同)共享同一页(映射到的物理地址相同)。