6.828笔记 Lab 3: User Environments
Lab3主要分为两个部分,第一部分是创建environment,也即是process进程。创建后会加载一个程序到第一个进程中,然后运行。第二部分是处理系统调用/中断/异常。
到分支Lab3以后,运行make qemu会出现kernel panic at kern/pmap.c:148: PADDR called with invalid kva 00000000,网上搜了一下,说是linker script的问题,修改kern/kernel.ld,把.bass修改为
1 | .bss : { |
就可以了。具体原因见这里。
User Environments and Exception Handling
进程
在此操作系统里,用Env表示用户进程。像pages一样,在kern/pmap.c中创建NENV个结构体Env,然后再把虚拟地址中UENVS映射到envs数组的物理地址。
- 映射做了以后,在
kern/env.c中完善一系列函数,主要是和分配env进程相关的。分配时,先分配一个page,让新分配进程的env_pgdir指向这页。再把UTOP以上除了UVPT(User Virtual Page Table)的其他地址的映射都设置为和内核页表kern_pgdir一样,所以就会和内核页表映射到相同的物理地址。UVPT映射到新进程自己的页表的物理地址。然后生成env_id,做一些初始化。新进程内保存的寄存器状态DS/ES/SS都设置为User Data,CS设置为User Text。esp指向USTACKTOP(0xeebfe000)。此时用户栈还未做映射。 - 加载一个程序到给定进程中时,要先换成进程的页表,然后类似之前在
boot/main.c中加载内核代码一样,加载给定的程序到用户进程的虚拟页表里。加载完后,设置进程的eip为程序的入口地址e_entry,映射虚拟地址中的用户栈0xeebfd000~0xeebfe000共4KB的空间到物理地址。 - 释放一个进程时,如果该进程是当前运行的进程,把使用的
cr3页表切换为内核页表。双重递归进程的页表,如果pte中哪一项存在,就把那一项映射到的page引用减1,pte置0。一个pde项查完后,把该pde项对应的page引用减1,页表对应位置置0。最后减引用进程页表对应的page,进程页表置0。进程放回env_free_list。
最后,在kern/init.c中,做了一些初始化后,创建了一个进程,加载user_hello程序到此进程,然后运行。user_hello的代码如下:
1 | // hello, world |
运行前,做了一些初始化,把cr3中的页表设置为用户进程的页表,然后env_pop_tf(&e->env_tf);。此函数内容为:
1 | void |
先把esp指针指向tf,也就是第一个envs[0]的env_tf,其实就是envs[0]的地址,因为env_tf是在结构体Env最前面的。然后popal是依次弹出栈中的内容(这里的栈其实就是envs[0].env_tf的空间结构),把弹出的值给到edi, esi, ebp, old esp, ebx, edx, ecx, eax。弹出的意思是把栈中的值赋给对应的寄存器,然后把esp加4。这和结构体Env的结构是相对应的。Env的第一个内容为:
1 | struct Trapframe env_tf; // Saved registers |
而Trapframe的内容为:
1 | struct PushRegs { |
然后的指令类似,把env_tf中的es, ds弹出到对应的寄存器,然后加8,跳过tf_trapno和tf_err。最后一条是iret(interupt return)。iret在权限变时(从内核态到用户态),弹出栈中的eip, cs, eflags, esp, ss到对应的寄存器;权限没变时,只弹eip, cs, eflags。iret执行完以后,对应的寄存器都是进程中保存的值了,最重要的是cs:eip和ss:esp,都指向了之前设置的用户程序的对应地址。再执行就开始执行用户程序了。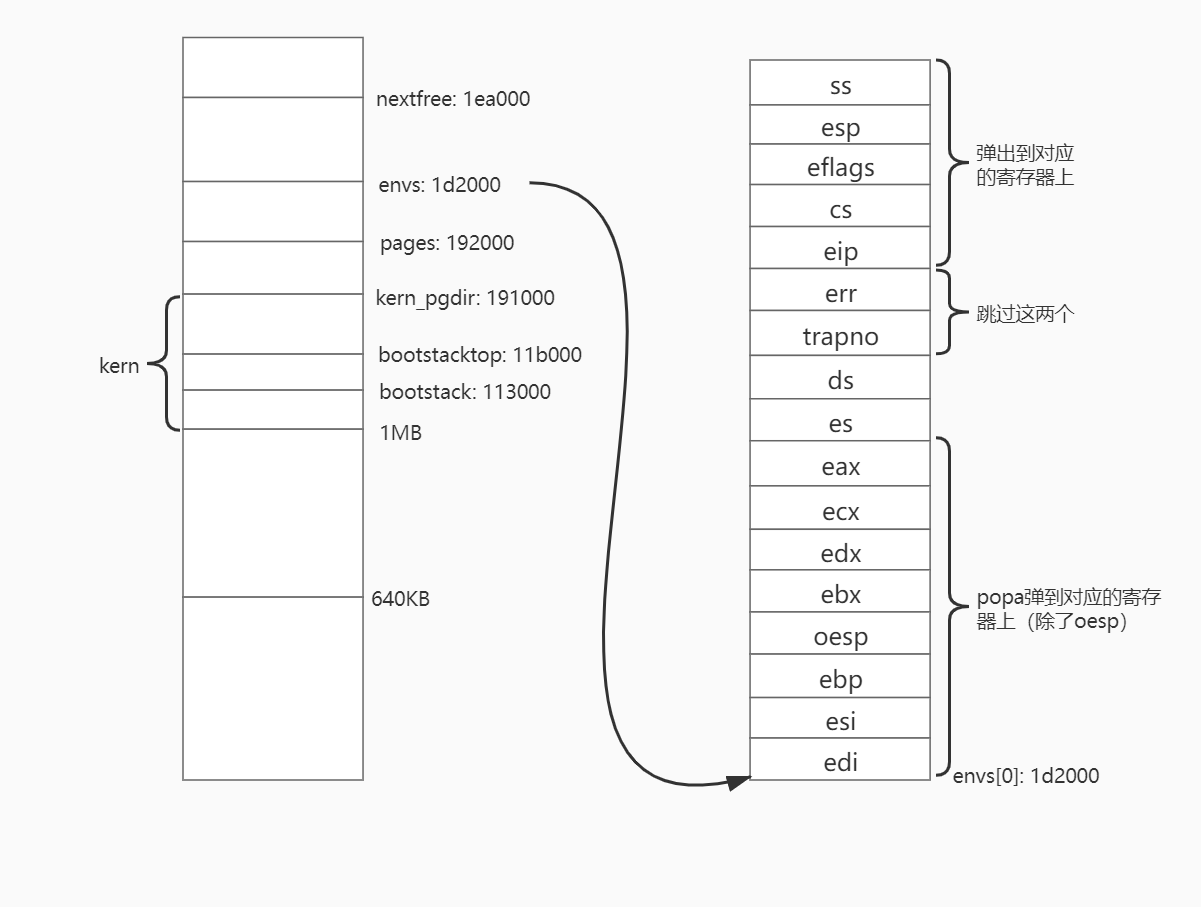
中断/异常
在kern/init.c中,运行的是user_hello程序。程序会一直运行直到800b44位置的第一个int $0x30指令。现在已经处于用户态,无法回到内核态。
中断和异常都是受保护的控制权转移,即让处理器不受用户态代码影响地从用户态切换到内核态。中断(interrupt)通常由处理器外部的异步事件(如外部设备I/O活动通知)引起。相反,异常(exception)是由当前运行的代码同步引起的,例如,由于被零除或无效的内存访问。为了保证这种控制权的转移是受保护的,所以在x86中,有以下两种机制共同达成这一目的:
- 中断描述符表(The Interrupt Descriptor Table):x86最多允许有256个不同的中断或者异常入口点进入内核,每个入口点具有不同的中断向量。中断向量是介于0和255之间的数字。不同的来源会生成不同的中断向量,如不同的设备、错误条件等。中断描述符表是在内核中的,格式如下:
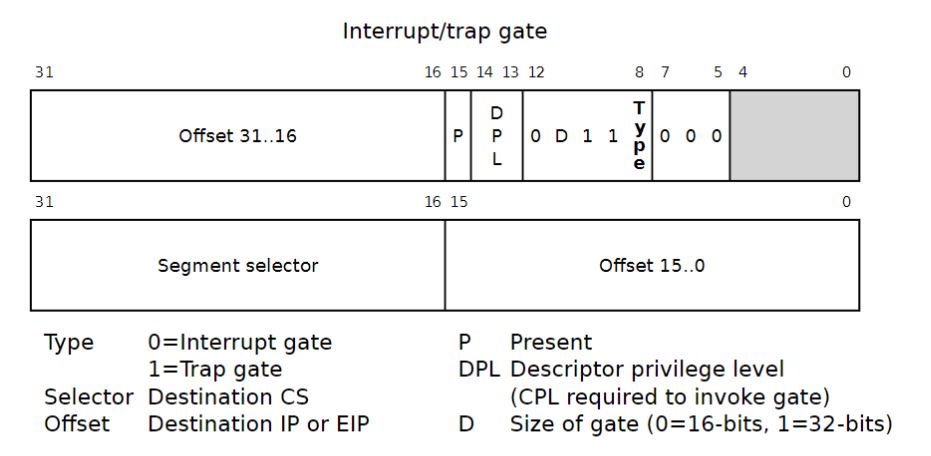
其中最重要的是Offset和Segment selector,分别对应eip和cs寄存器,通过这两个就可以得到处理中断/异常的代码。 - 任务状态段(The Task State Segment):在进行中断响应前,要保存之前进程的状态,即各个寄存器的值。而为了避免受到用户代码的影响,所以把之前进程的寄存器的值保存在内核栈中。任务状态段的作用就是存储内核栈的信息包括
esp和ss。其实TSS包括的内容很多,可以存储其他更多内容,但是在此操作系统里,只用了esp0和ss0两个内容,值分别为KSTACKTOP和GD_KD。esp0和ss0中的0代表最高特权级。
x86处理器内部生成的所有同步异常都使用0到31之间的中断向量。大于31都是软件中断或者是异步硬件中断。
中断/异常处理流程
在用户代码的执行过程中,如果发生了中断/异常,处理器会执行以下操作:
- 把
TSS(能在GDT中找到)里面的esp0和ss0加载到对应的esp和ss寄存器中,值分别为KSTACKTOP和GD_KD。 - 通过中断向量和
IDT的基地址,找到对应的中断描述符(IDT的基地址+中断向量*8,*8是因为一个中断描述符长度为8字节)。把其中的Segment Selector(GD_KT)和Offset(eip)(函数名也能代表地址)加载到cs和eip中,此时eip已经指向内核代码中的中断处理程序。 - 因为
esp已经指向KSTACKTOP,push old ss, push old esp, push old eflags, push old cs, push old eip。即保存当前用户进程的状态到内核栈。当然,这没有处理完,还有些寄存器的值没有保存,这部分是下一步在操作系统中实现的。 - 此时
cs:eip和ss:esp都指向内核,执行操作系统中中断/异常处理程序。
注意:
1. 上述过程是经过简化的,实际上还要检查权限位等操作。
2. 有些中断除了push那5个寄存器的值,还需要push error code。
3. 从用户态到内核态时,需要保存原来的栈的信息(ss和esp)。但是如果发生中断/异常时,已经处于内核态了,就不需要保存了,因为本来就在内核栈中,只需要push old eflags, push old cs, push old eip。这和之前的iret在不同权限转换情况下的处理是相对应的。
4. 以上push的值和接下来操作系统push的值都是push到内核栈(以KSTACKTOP=0xf0000000为顶部,因为设置的esp就是这个地方)。
下面这张图说明了这几种情况: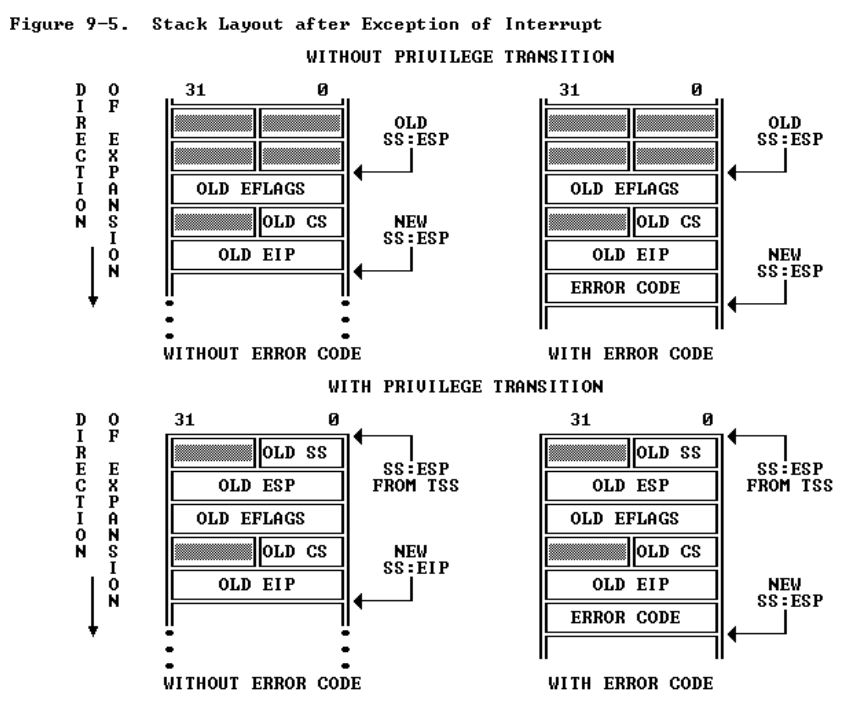
以上是处理器的操作,此时cs:eip和ss:esp都指向内核空间,下一步是执行操作系统中中断/异常处理程序。其中,ss和esp是在TSS中定义的,而TSS是在kern/trap.c/trap_init_percpu()中定义的,cs和eip是在kern/trapentry.S和kern/trap.c/trap_init()中共同定义的。每种处理程序先push 0作为error code(如果处理器已经push了则不需要),然后push中断向量(0~255的数字,也就是上图中的trapno),然后跳转到_alltraps函数:
1 | _alltraps: |
其实就是用前三行又构造了一个和上图中一样的Trapframe,然后把此Trapframe的地址(esp)放入栈中,作为参数传给kern/trap.c/trap()。此时已经能够处理一些异常了。
验证1
执行user_hello程序,800b44是int $0x30,在此处打断点,此时各个寄存器的值为:
1 | eax 0x0 0 |
然后:
1 | (gdb) si |
中断是int $0x30,$0x30是48,定义为系统调用,处理器不放error code,需要处理程序自己加上去。esp指向KSTACKTOP。刚开始进入内核前,在kern/entry.S里面,把esp设置为f011b000,物理地址为11b000,也就是bootstacktop。bootstack是f0113000,栈的长度是0x8000字节,即32KB。然后在kern/pmap.c中通过
1 | boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W); |
把虚拟地址中的KSTACKTOP-KSTKSIZE到KSTACKTOP的32KB的地址映射到物理地址中的bootstack到bootstacktop。也就是说,刚开始在kern/init.c和kern/pmap.c中,做上述映射之前,使用的的确是物理地址里内核部分里面的32KB的栈,但这时候还没有做映射。然后通过上面那句话做了映射,后面的代码中使用到虚拟地址为0xf0000000的KSTACKTOP的时候就映射到物理地址的11b000。
在执行int指令之前,esp是0xeebfde54,进程中定义的用户栈。int指令会把tss里的ts_esp0拿出来赋给esp,而ts_esp0就是KSTACKTOP,0xf0000000。然后在此栈中push5个值(但是不知道为啥在这里还会多执行后面的一句话,再push一个0进去作为error code,但是影响不大)。
执行int前进入ctrl+a c进入qemu的调试,查看物理地址
1 | (qemu) xp/x 0x11b000 |
0x11b000是实际内核栈映射到的位置的上面的了,0x11affc是0x11b000下面的第一个字,也就是现在栈中最早入栈的数据。执行int指令后,esp变为0xefffffe8,和0xf0000000相差6个字,和上面的分析一致。此时查看物理地址:
1 | (qemu) xp/7x 0x11afe8 |
0x11afe8是0x11b000下面6个字的位置。前面6个分别为error code, old eip, old cs, old eflags, old esp, old ss。0x11b000位置的0x00000003还在那,其他的被覆盖了。
另外,ebp在中断前后的值是不变的。
验证2
也可以看看IDT。
1 | p *idt@50 |
p *idt@50是查看idt这个数组的前面50个(从0开始计数),系统调用是48,即倒数第二个。gd_off_15_0是17578,十六进制是44aa,gd_off_31_16是61456,十六进制是f010,合在一起是f01044aa。在obj/kern/kernel.asm中:
1 | f01044aa <t_syscall>: |
正是处理程序的首地址。
Page Faults, Breakpoints Exceptions, and System Calls
在这一部分,先要处理Page Faults和Breakpoint Exception。需要添加的代码比较简单。
1 | static void |
Lab中的Question 3也说了,断点测试有可能会生成break point exception或者是general protection fault,到底生成哪个取决于怎么初始化IDT的。初始化IDT中break的代码为
1 | SETGATE(idt[T_BRKPT], 0, GD_KT, t_brkpt, 3) |
其中,0代表是中断,GD_KT代表内核代码段(起始地址为0,范围为4GB),t_brkpt代表声明的函数,也即函数的地址(偏移量),3代表dpl(Descriptor Privilege Level)。关于这个参数,代码中的注释为
1 | the privilege level required for software to invoke this |
软件使用int指令显式调用此中断/陷阱门所需的特权级别。也就是说,在断点测试的代码
1 | asm volatile("int $3"); |
中的显式调用int的指令,需要cpl<=3。现在先接着之前讲到的中断/异常处理流程,讲一下处理前特权位的检查。这部分处理是在之前的处理流程的前面完成的。
中断/异常特权位的检查
- 检查
eflags上的PE等位,使CPU知道这是在保护模式下。如果是软件中断,并且对应IDT中的描述符的dpl<cpl,则发出general protection exception。也就是说,必须满足cpl<=dpl,当前的特权级必须与该中断/异常要求的特权级相等或者比其高,才能触发该中断/异常。否则,在用户代码里就可以随便用汇编语言触发中断/异常,这也就没有保护、隔离可言了。 - 读取对应描述符中
code segment selector对应的descriptor,也就是GDT中的段描述符,在这里是kernel text对应的描述符。检查此描述符的dpl,如果大于cpl,则发出general protection exception。意思就是必须满足cpl>=dpl,也就是说要么权限不变(在内核处理中断时,又产生了中断,此时权限不变),要么提高权限(从用户态到内核态),不能降低权限(从内核态到用户态,是使用iret实现的,而不是中断)。
刚开始我没注意到步骤二中的dpl到底是哪个,以为还是步骤一当中的dpl,我还说为什么步骤一中cpl<=dpl,步骤二中又要cpl>=dpl,这不是矛盾了吗。后来才看到,步骤二中比较的dpl不是IDT描述符的dpl,而是要切换到的code segment selector在GDT中的dpl,此dpl代表要切换到的模式的特权级。步骤二的比较规定了不能从内核态切换到用户态,只能从用户态到内核态或者保持内核态不变。
现在书接上文,使用
1 | SETGATE(idt[T_BRKPT], 0, GD_KT, t_brkpt, 3) |
定义的中断处理,就会触发断点中断,最后打印出的信息里显示的是Breakpoint。而如果改成
1 | SETGATE(idt[T_BRKPT], 0, GD_KT, t_brkpt, 0) |
最后打印的是General Protection,说明没有通过上文特权位检查的步骤一。同理,把softint的定义改为
1 | SETGATE(idt[T_PGFLT], 0, GD_KT, t_pgflt, 3) |
会打印出Page Fault。但是测试程序需要运行此程序打印General Protection,所以还是改为0。
系统调用
使用int $0x30作为系统调用。现在就比较明确,在idt中声明系统调用时dpl为3,否则用户进程无法生成中断。
现在有两个文件夹,分别叫lib和kern,里面分别有syscall.c和syscall.h,前者是用户态下的相关文件,后者是内核态下相关的文件。调用流程如下:
- 用户代码里与调用普通函数类似,调用系统调用。如在后面在
lib/libmain.c中添加的1
envid_t envid = sys_getenvid();
- 接下来会调用
lib/syscall.c中对应的函数,而此函数又调用同一文件中的syscall()函数1
return syscall(SYS_getenvid, 0, 0, 0, 0, 0, 0);
syscall()代码为汇编代码的格式为指令 : 输出 : 输入 : 该指令可能改变的内容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33static inline int32_t
syscall(int num, int check, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
int32_t ret;
// Generic system call: pass system call number in AX,
// up to five parameters in DX, CX, BX, DI, SI.
// Interrupt kernel with T_SYSCALL.
//
// The "volatile" tells the assembler not to optimize
// this instruction away just because we don't use the
// return value.
//
// The last clause tells the assembler that this can
// potentially change the condition codes and arbitrary
// memory locations.
asm volatile("int %1\n"
: "=a" (ret)
: "i" (T_SYSCALL),
"a" (num),
"d" (a1),
"c" (a2),
"b" (a3),
"D" (a4),
"S" (a5)
: "cc", "memory");
if(check && ret > 0)
panic("syscall %d returned %d (> 0)", num, ret);
return ret;
}T_SYSCALL为48,写成十六进制就是int $0x30,num是具体的系统调用号,放到a中,也就是eax。a1到a5是5个参数,可以不用完,放到d、c、b、D、S中,分别对应edx, ecx, ebx, edi, esi。把值放进对应寄存器后,再运行int指令。最后返回值放到ret中。- 把值放进对应寄存器后,运行
int指令,也就是按照上面写的检查特权位和执行流程进行,此时CPU才会把这些寄存器的值压入内核栈,间接地给内核的系统调用程序传递了参数。上面的代码也写了内核处理系统调用的程序,把tf中对应的寄存器作为参数,传递给kern/syscall.c/syscall(),返回值放进tf的eax。 - 在
kern/syscall.c/syscall()中,根据syscallno(也就是步骤三中放到eax中的num)分别调用对应的函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int32_t
syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5)
{
switch (syscallno) {
case SYS_cputs:
sys_cputs((const char *)a1, a2);
return 0;
case SYS_cgetc:
return sys_cgetc();
case SYS_getenvid:
return sys_getenvid();
case SYS_env_destroy:
return sys_env_destroy(a1);
default:
return -E_INVAL;
}
} - 执行完毕后,在
kern/trap.c/trap()中通过env_run(curenv);从内核态回到用户态。从内核态到用户态的最后一句是iret。回去后用户代码从eax里获取返回值。
上面的六条,前三条用的是lib下的syscall,后三条用的是kern下的syscall。所以,lib中的代码更像是给用户代码提供了一个接口,经过一些处理后,进入内核态,用kern中对应的代码实现。
此时,一些中断和系统调用已经实现,下面以user/hello.c为例子。进入用户态前,先运行lib/entry.S,做一些设置,然后调用lib/libmain.c/libmain(),其代码为:
1 | void |
先使用系统调用sys_getenvid()获取envid,然后调用umain(),也就是主程序。代码为
1 | void |
两次cprintf,也就是两次系统调用,执行完后执行lib/libmain.c/libmain()中的exit(),代码为
1 | void |
也是系统调用。所以在整个程序的运行过程中,一共四次系统调用。事实上也的确是这样。每次在kern/trap.c/trap()中都会打印出一句cprintf("Incoming TRAP frame at %p\n", tf);,而运行user/hello.c也一共打印了4次。
1 | [00000000] new env 00001000 |
在做这次Lab的时候,有一点疑惑,就是为什么有些IDT的dpl设置为0了,用户代码还是能够执行这些异常。后来,经过一些断点调试,发现大部分异常是通过CPU在执行指令的过程中发出的。比如user/divzero,里面有cprintf产生中断,但是在此之前,就已经在80005c: idiv,做除法的过程中产生了异常,进入了内核。或者是user/faultread,在cprintf中断前执行其他指令的时候就已经产生异常了。这些异常发生后,没有检查idt中的特权位dpl,直接按照之前写的中断/异常的处理流程进行处理,最终进入内核。而几个在用户代码里直接用汇编发出中断/异常的,如果dpl为3,则是可以的,为0的话就会产生general protection exception,这个在之前已经说过了。
具体的官方描述如下(Intel 64 and IA-32 Intel Architecture Software Developer’s Manuals Volume 3A: System Programming Guide, Part 1 5.12.1.1):
1 | The processor does not permit transfer of execution to an exception- or |
这段话解释把上面一些问题解释得很清楚了。
按照Lab中的说法,0到31的中断向量是x86处理器生成的(处理器在执行某条指令的过程中生成的),大于31的中断向量由软件中断生成(使用int指令)或者是由异步硬件中断生成(外部硬件设备)。本次Lab中实现了0到31的处理器生成异常的处理以及48号软件中断(被用于系统调用)。下一个Lab会处理一些外部生成的硬件中断,比如时钟中断。